一个小的点:Memory时而翻译为内存时而翻译为存储器。
6.2Memory Type
按存取方式
随机访问
- RAM:random access
- DRAM: dynamic
- 电容器capacitor,需要频繁刷新
- cheaper
- SRAM: static
- D触发器flip-flop
- faster,用于构建cache
- DRAM: dynamic
- ROM: read-only
串行访问
- 顺序存取存储器
- 直接存取存储器
按存储介质
- 半导体存储器:TTL、MOS,易失性
- 磁表面存储器
- 磁芯存储器
- 光盘存储器
按作用
- 主存
- RAM
- ROM
- Flash Memory
- 高速缓存
- 辅存
6.3内存的层次结构
在存储层次中越往上,存储介质的访问速度越快,价格也越高,相对存储容量也越小。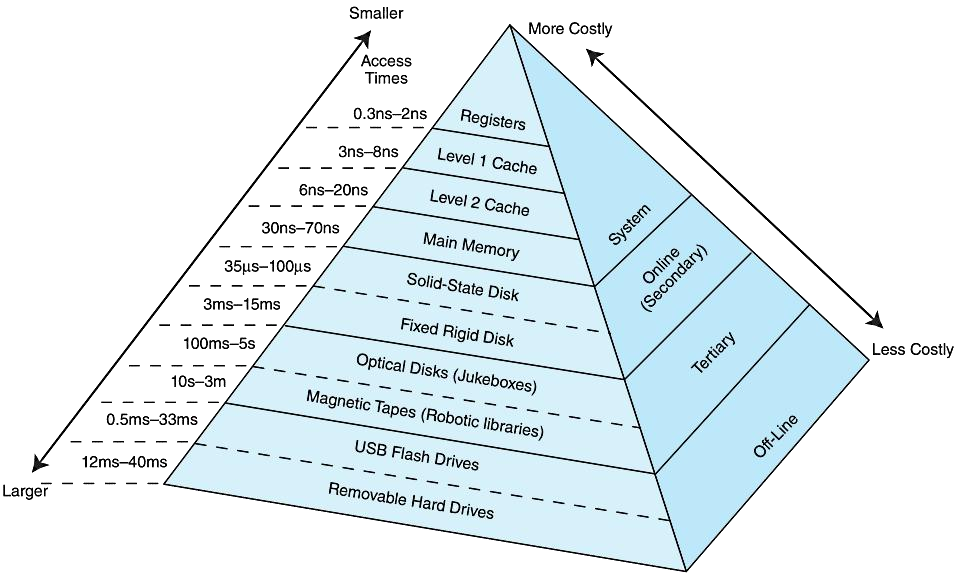
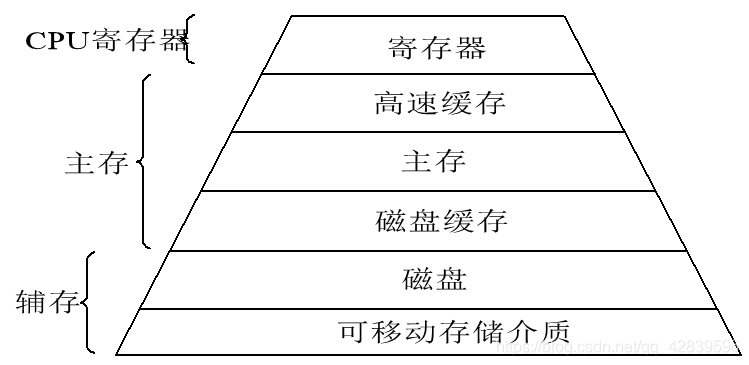
6.4高速缓存
主存按地址访问,缓存按内容访问(内容可寻址存储器)
- 命中hit
- 命中后复制整个数据块block
- 失效miss
- 失效后去内存中将整块的数据copy到缓存中
- 局部性原理locality
关于这些映射最好看看书上的例题
直接映射
direct mapped cache
N个缓存块组成的直接映射缓存中,主内存块X映射到缓存块Y = X mod N 。
主存地址格式: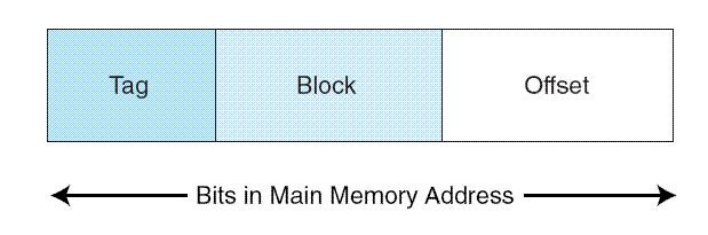
- offset偏移字段,块内偏移
- block块字段,选择缓存块
- tag标记字段,用总位数(根据主存总容量确定)减前两个字段
全相联映射
fully associative cache
只有标记字段和偏移字段,随机选择缓存块
组相联映射
set associative cache,结合了前两个:选组为mod,组内为随机选择
- set字段为选择缓存块的分组
- 只有一组时即为全相联映射
- 一组只有一块时即为直接映射
- 2-way set associative mapping:2路组相联,即每个组里面有2个block
替换策略
- OPT最佳置换optimization algorithm
- LRU最近最少使用least recently used,回顾过去,换出最长时间未使用的块
- 缺点:复杂
- FIFO先进先出,换出存在缓存中最长时间的块
- 随机替换策略random replacement
- 优点:不会颠簸thrash
有效访问时间
effective access time
EAT=$H×Access_c+(1-H)×Access_{MM}$
- H是命中率=命中次数/总访问次数
- $Access_c$是缓存访问时间
- $Access_{MM}$是主存访问时间
- 访问重叠 overlap即同时访问高速缓存和主存
- 访问重叠:$Access_{MM}$是主存访问时间
- 访问不重叠:$Access_{MM}$是主存访问时间+缓存访问时间
写策略
脏块:在缓存中已被更新的块,必须写回内存
- write through直写:每次写入时同时写入更新缓存和主内存
- 缺点:每次缓存写入都必须更新内存
- write back回写:仅在选择要替换的块时更新内存
- 缺点:内存并不总是与缓存中的值一致,导致在具有许多并发用户的系统中出现问题。
- 优点:内存流量最小化
6.5虚拟内存
virtual memory,我浅显的理解就是跟缓存类似,都是跟主存间的映射关系
分页
- physical address
- virtual address
- page faults页面错误,缺页?没有在主存中找到页面,需要从硬盘中获取时
- 主存和虚存的页面大小相等,因此偏移字段的位数相等
- pagetable页表:虚页号+有效位
虚页与主存页面的转换看例题
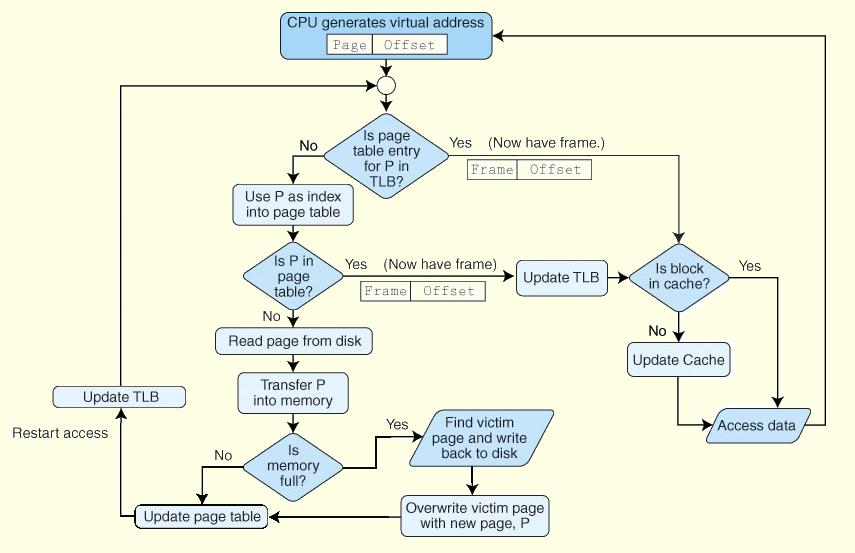
- TLB
- 页表=虚页号+页号
TLB+页表+主存
分段
segmentation,长度可变,根据内存大小分配段
碎片
fragmentation
- 内部碎片internal:分页导致
- 外部碎片external:分段导致
- 可通过压缩进行恢复?
段页式
页式:页表查询较慢,但由于规范的映射,获取数据较快
段式:相反
段页式:结合paging and segmentation,每一段中存放一个页表
作业
1.直接映射

分块=总存储容量/块的大小
缓存中地址表示=tag+cache block+offset,tag由总的地址大小(主存总容量)减去后两个得到,即主存的前x位
主存地址映射到缓存→主存的块MOD缓存的块
11.缓存命中
the hit ratio=命中/总的访问
替换:根据tag字段放入对应的block
20.分页式
确定地址位:页号+偏移量
地址转换:页表for页号,偏移量不变