网络攻防第一步信息收集部分的概念和实验(子域名收集、主机扫描、端口扫描)。
理论
信息收集是指黑客为了更加有效地实施攻击而在攻击前或攻击过程中对目标的所有探测活动。
公开信息收集
web服务
- 网站所有者信息:邮箱、地址、公司人员
- 网站服务器对应的IP
- 目标网络拓扑结构:子域名
搜索引擎
Google Hacking:语法、关键字→网站配置信息、后门信息
语法:
- and ,or, +, -, “”, .(单字符匹配), *(0或多字符匹配)
- site, link, inurl, intitle, intext. filetype
Shodan,ZoomEye
WhoIs服务
查询已注册域名的拥有者信息
查询途径:
- 网站,如站长之家http://whois.chinaz.com/
- 企业的备案信息:如国家企业信用信息公示系统、ICP备案查询网
DNS域名服务
如果DNS配置不当,可能造成内部主机名和IP地址对的泄露
- CDN
- nslookup
网络扫描
有些操作系统实现TCP/IP时并没有完全遵循RFC标准,导致部分扫描看不到效果。
主机扫描
- ping:request8,reply0
- 在IP头中设置无效的字段值:向目标主机发送包头错误的IP包,目标主机或过滤设备会 反馈ICMP Parameter Problem Error信息。
- 错误的数据分片:向目标主机发送的IP包中填充错误的分段值,目标主机或 过滤设备会反馈ICMP Destination Unreachable信息。
端口扫描
- TCP扫描:connect、SYN、NULL、Xmas、ACK、FIN
- UDP扫描
系统扫描
- 根据端口扫描结果分析,操作系统的特有功能会打开特定的端口
- 连接服务器程序时所给出的欢迎信息BANNER:FTP、SSH、Telnet
- TCP/IP协议栈指纹:不同的操作系统在实现TCP/IP协议栈时都或多或少地存在着差异。而这些 差异,我们就称之为TCP/IP协议栈指纹。
漏洞扫描
漏洞数据库:X-Force,CVE、国家漏洞库
漏洞检测技术:
- 被动式策略:基于主机,检查安全规则
- 主动式策略:基于网络,执行脚本攻击
漏洞检测方法:
- 直接测试:具有针对性,需要根据漏洞特点进行排查,可能对系统造成破坏
- 推断:版本检查、程序行为分析、操 作系统堆栈指纹分析和时序分析等
- 带凭证的测试:具有用户权限
网络拓朴探测
- 拓扑探测:traceroute、SNMP
- 网络设备识别
- 网络实体IP地理位置定位
实践
1子域名收集
实验目的
通过python脚本实现qq.com子域名的收集,分别输出必应和百度两个搜索引擎的结果。
实验过程
导入必要的包
1 | import requests # 用于请求网页 |
使用百度搜索domain:qq.com,观察网络请求和响应的具体情况。根据请求头分别定义headers和url两个变量,通过requests向指定网页发起指定请求,并通过BeautifulSoup解析响应返回的网页源码html格式。
1 | hearders = { |
观察源码,定位域名url的具体位置,从格式化数据中搜索获取url和title,一条搜素结果所在的div如下:
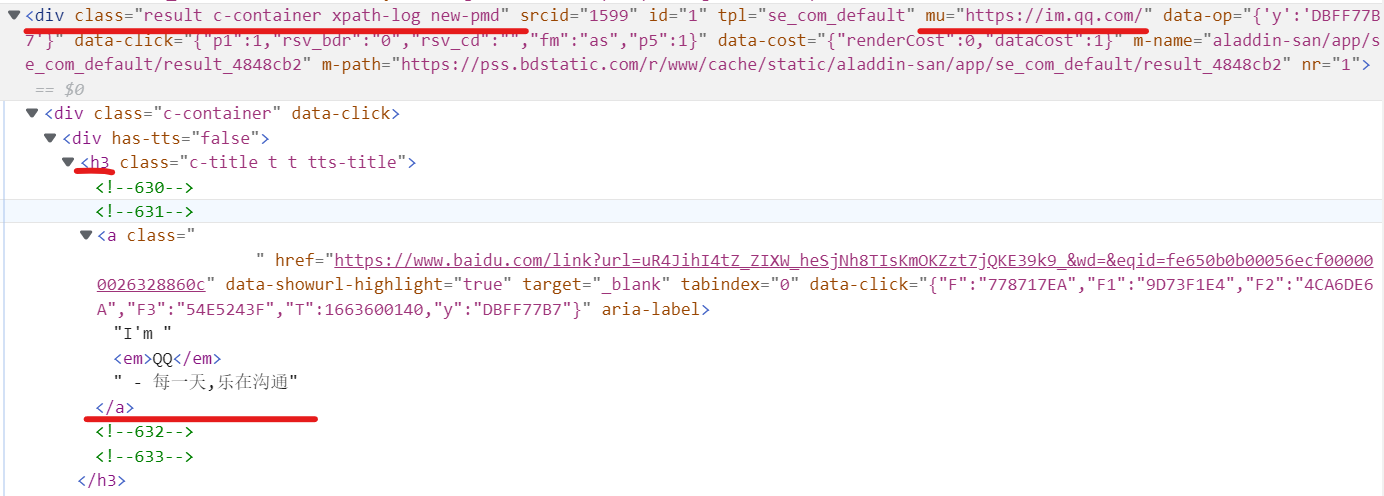
1 | #定位每一条搜索结果 |
实验结果
根据输入选择搜索引擎,实验结果如下:

结论:不同搜索引擎的结果有明显不同。由于未做翻页处理,实验数据来源仅为第一页网页,可能与搜索引擎的排序算法有关。
待改进:1.翻页处理可以获得尽可能多的子域名;2.暂时不可以指定主域名。
2主机探测&端口扫描
实验目的
- 使用ICMP协议探测主机是否开启;
- 分别对本机和远程服务器进行半连接的端口扫描,并与nmap扫描结果进行对比分析;
- 理解
conf.L3socket=L3RawSocket的作用
实验环境
Windows 10,Ubuntu22.04,python3.8,vscode,wireshark,nmap
实验过程
首先conf.L3socket=L3RawSocket修改scapy的配置文件,作用时使用scapy发送包时使用原生套接字。
主机探测
主要用到了scapy中的ICMP,对目标主机发送ICMP包,如果有回复(响应不为None)则表示目标主机是存活状态。
1 | packet=IP(dst=ip)/ICMP() # 制作一个ICMP包 |
端口扫描
都是利用scapy中的TCP,对目标主机发起连接请求,根据TCP包的标志位选择的不同会有不同的回复情况。
首先定义一个数组存放标志位,实现根据用户的输入选择不同的方法进行扫描:
1 | choices=[['S','SA'],['F'],['FPU'],['']] |
发送TCP包
这几个扫描方法的共同之处就是都会发送tcp包
1 | p = IP(dst=ip) / TCP(dport=int(port), flags=flag) # 根据对应的标志位制作TCP包 |
FIN&NULL&Xmas
这三个扫描办法的原理类似,如果发送后没有回复表示该端口开启。
Xmas扫描:只要不包含SYN,RST,或者ACK, 任何其它三种(FIN,PSH,and URG)的组合都行。
SYN
需要判断响应包的标志位ans['TCP'].flags,发送SYN后,若返回SA则端口开放;
实验结果略
L3RawSocket
scapy在默认情况下是无法直接发送ICMP包到本机的,在Linux上需要设置conf.L3socket=L3RawSocket,采用原生套接字接口发送。而在Windows上需要配合Npcap使用,选择wireshark的loopback capture功能即可开启Npcap功能,捕获环回地址的包,结果如图:
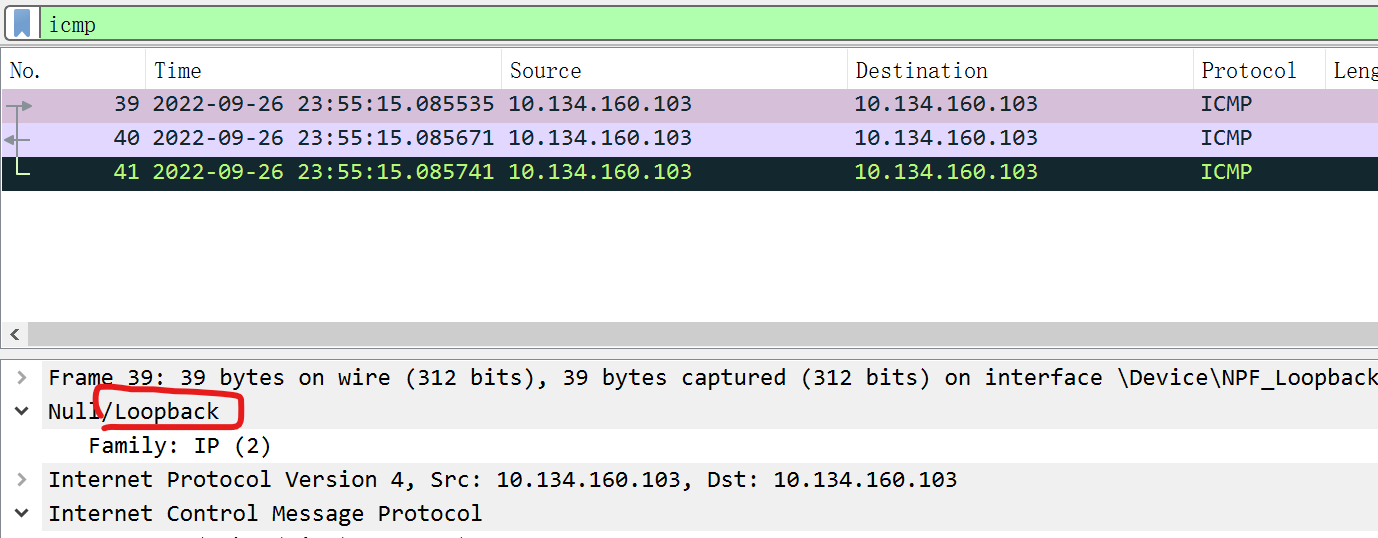
待深入
- 非RFC兼容的主机可能以不正确的方式响应扫描探测;
- 包在回环地址的具体流动情况;
- 防火墙相关。
参考资料
端口扫描部分原理:
scapy如何作用于本机:https://scapy.readthedocs.io/en/latest/troubleshooting.html
如何用wireshark捕获环回地址上的流量:https://wiki.wireshark.org/CaptureSetup/Loopback