针对口令的攻击与防范,涉及实验:SEED Labs – MD5 Collision Attack Lab,代码见:https://github.com/Seanxz401/seed-labs
理论
身份认证
针对口令强度的攻击
- 字典攻击:统计使用概率高的
- 暴力破解:排列组合
- 撞库攻击:根据网络上已泄露的数据
- 彩虹表攻击:破解MD5、HASH
针对口令存储的攻击
Linux口令存储:/etc/password和/etc/shadow
shadow文件中密码字段的组成:算法、salt、密码哈希值(多轮哈希可减缓暴力破解)
salt:加盐,就是在哈希时添加随机字符串,防止字典攻击和彩虹表攻击
Windows口令存储:
1 | %systemroot%system32\config\目录下 |
SAM文件:系统保存sam文件时将sam信息经过压缩处理,因此 不具有可读性。
NTLM认证协议:将口令转换为Unicode字符串,用MD4对口令进行单向HASH,
本地获取口令:硬盘、内存、破解SAM信息
口令破解原理:尝试用已知算法加密单词,然后对比获取到的结果
针对口令传输的攻击
- 嗅探攻击:混杂模式
- 键盘记录
- 网络钓鱼
- 重放攻击
口令防范
- 密码强度:长度、大小写字母+数字+特殊符号
- 防止口令猜测攻击
- 设置安全策略
实验-MD5碰撞
实验目的
a) 使用md5collgen生成两个MD5值相同的文件,并利用bless十六进制编辑器查看输出的两个文件,描述你观察到的情况;
b) 参考Lab3_task2.c的代码,生成两个MD5值相同但输出不同的两个可执行文件。
c) 参考Lab3_task3.c的代码,生成两个MD5值相同但代码行为不相同的可执行文件。
d) 回答问题:通过上面的实验,请解释为什么可以做到不同行为的两个可执行文件具有相同的MD5值?
实验环境
Ubuntu20.04,gcc9.3.0,md5collgen
原理介绍
md5collgen工具
由前缀生成MD5碰撞,即返回两个md5值相同的文件,但是内容不完全相同,为前缀+128字节填充
md5算法原理
MD5将输入数据划分为64个字节的块,然后在这些块上迭代计算散列。第一次迭代的IHV输入(IHV0)是一个固定的值。因此,将特定的suffix添加到具有相同 MD5 散列的任何两个不同消息中,通过连接原始消息和suffix消息,得到两个新的更长消息,这两个消息也具有相同的 MD5 散列。给定两个输入M,N如果MD5(M) = MD5(N),那么对于任何输入T,MD5(M || T) = MD5(N || T)。
一些命令
cat
1 | # 将多个文件连接为一个文件 |
head tail
1 | # 将file1中前x个字节写入file2,-c表示读取的二进制文件 |
注:地址是从0开始的。
实验过程
a)md5collgen生成两个md5相同的文件
先创建一个文本文件test.txt
1 | md5collgen -p test.txt -o out1.bin out2.bin |
查看两文件的md5值:相同
查看十六进制:前缀相同(都是test.txt),填充内容有不同之处(但是md5相同)。
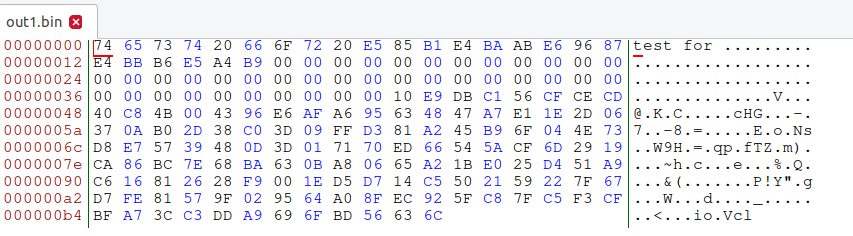
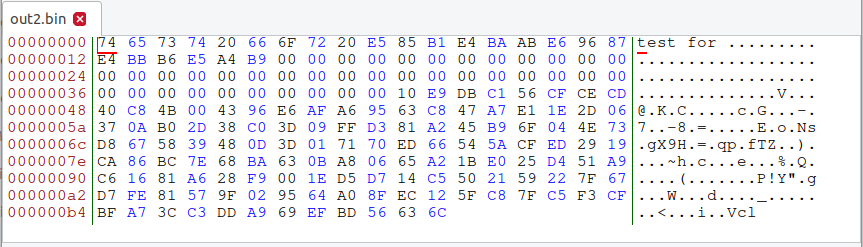
b)生成两个MD5值相同但输出不同的两个可执行文件
填充数组,编译c文件生成a.out,使用bless查看,定位输出的数组:
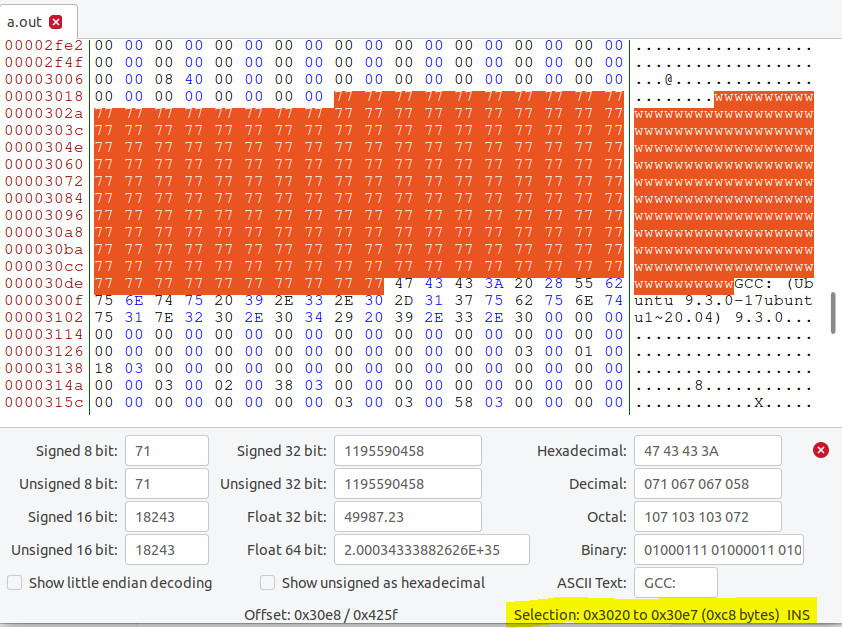
输出数组范围在0x30200x30e7,转为十进制为1232012519,选择12352(凑64的整数倍)之前的作为prefix,中间改128字节,因此把12352+128=12480 后面的截取出来作为suffix:
1 | head -c 12352 a.out > prefix |
根据 prefix 生成 md5 相同的两个文件
1 | md5collgen -p prefix -o out1.bin out2.bin |
取out1.bin out2.bin的后128字节:
1 | tail -c 128 out1.bin > P |
将三部分进行拼接,并对生成的文件赋予执行权限:
1 | cat prefix P suffix > a1.out |
执行a1.out a2.out输出结果如图,有不同之处,因为数组中间修改了一部分:
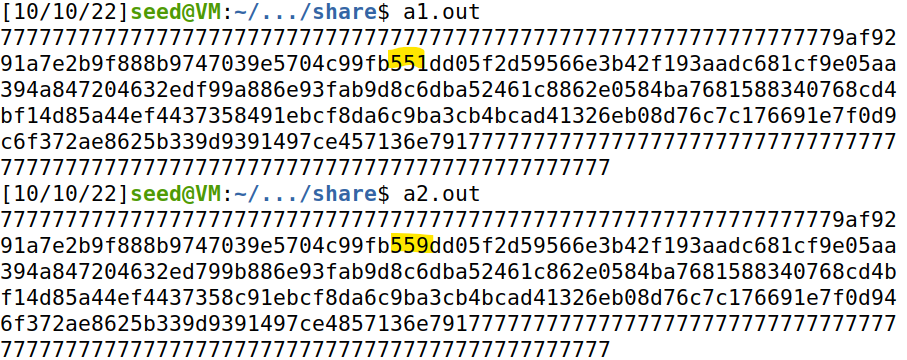
查看两个执行文件的md5值,结果相同:

c)生成两个MD5值相同但代码行为不相同的可执行文件
分别创建两个值相等的数组arr1,arr2,
1 | unsigned char arr1[200] ={...}; |
直接编译执行输出”benign code”
查看编译结果如下:
arr1:0x30200x30e7(1232012519)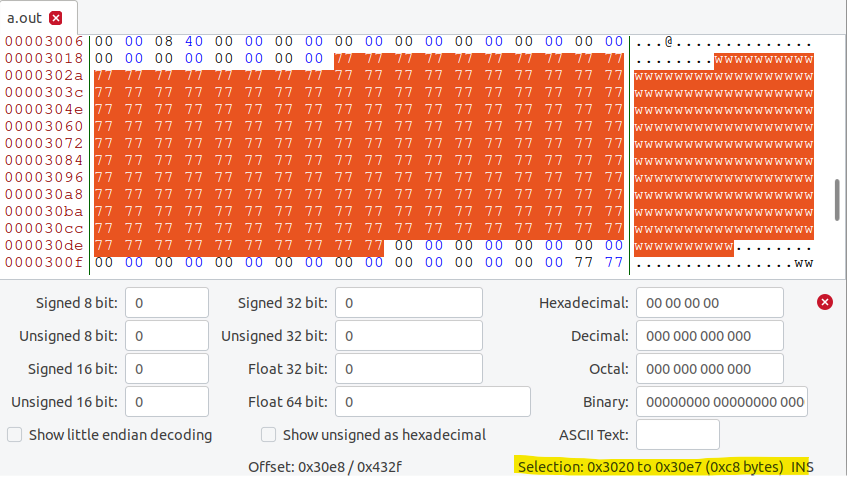
arr2:0x31000x31c7(1254412743)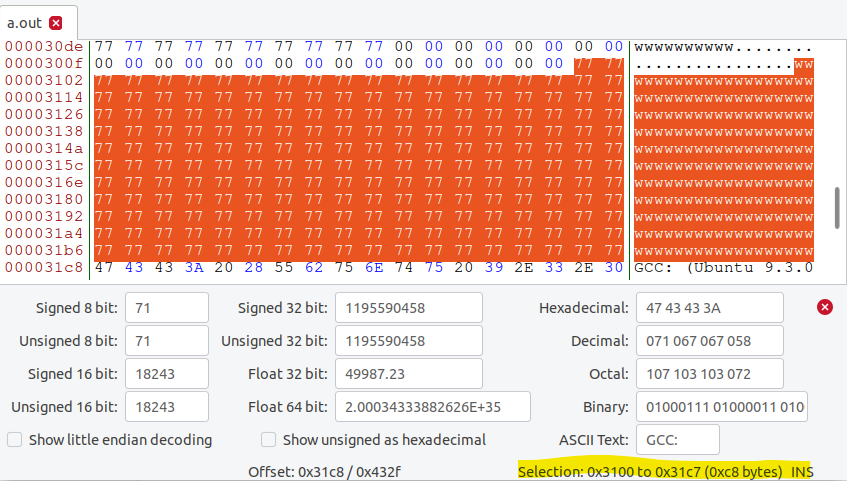
arr1的位置与任务二相同,截取前12352作为前缀并生成两个md5相同的文件:
1 | head -c 12352 a.out > prefix |
截取后缀(从GCC开始)
1 | tail -c +12745 a.out > suffix |
把其中一个新前缀p的后32(字符A)+128(md5填充物)=160个字节截取出来作为第二个数组的主体:
1 | tail -c 160 out1.bin > middle |
获取填充字节0x00,由于数组200个字节,因此填充40个,注意两个数组间还有24字节的填充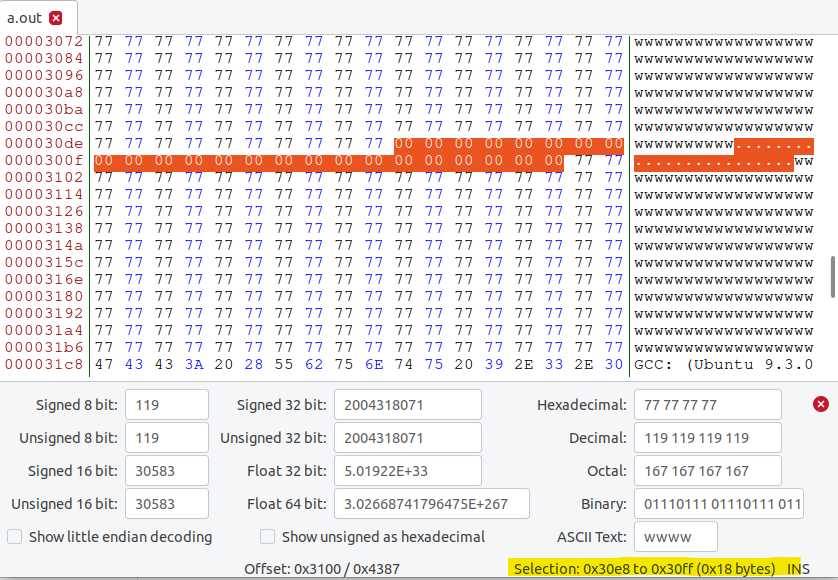
1 | head -c 12544 a.out > temp |
开始拼接:
1 | cat out1.bin m40 m24 middle m40 suffix > a1.out |
赋予权限并执行: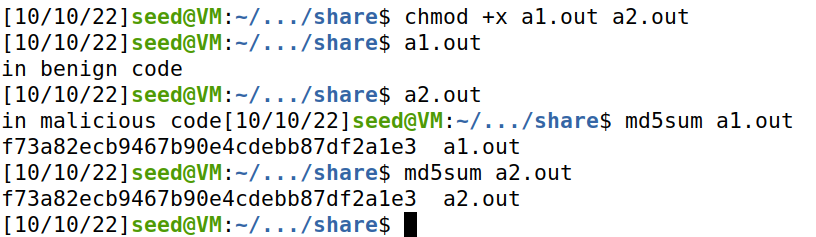
由图可得两个文件执行的函数不同(因为数组的值改变了),但是md5值相同。
d)对c任务的解释
不同行为:在最后生成的可执行程序中,第二个数组与源程序无关,完全来自于第一个数组,因为middle取自out1.bin;因此经过填充后,两个文件中第二个数组的与其中一个相同而与(md5collgen产生的)另一个不相同导致if判断产生不一样的结果,最后执行不一样的函数。
相同md5:out1.bin与out2.bin是由md5collgen产生的具有相同md5值的不同prefix文件,而两个文件后面的填充+middle+suffix完全相同,因此在迭代运算中保持着相同的md5导致最后计算结果一样。
参考
MD5 Collision Attack Lab seed solution - SKPrimin - 博客园 (cnblogs.com)
[从入门到入土:[SEED-Lab]MD5碰撞试验|MD5collgen实验|linux|Ubuntu|MD5 Collision Attack Lab|详细讲解_桃地睡不着的博客-CSDN博客](https://blog.csdn.net/Q_U_A_R_T_E_R/article/details/120455905)
[网络攻防技术——MD5碰撞试验_啦啦啦啦啦啦啦噜噜的博客-CSDN博客_md5碰撞](